
Platform
DATA ANNOTATION AND VALIDATION PLATFORM
The data annotation and validation platform designed for the most complex computer vision, traditional, and Gen AI models.
- Iterative quality and calibration processes that scale
- A collaborative space for project management and reporting
- Proactive human and tech-driven insights keep models on track

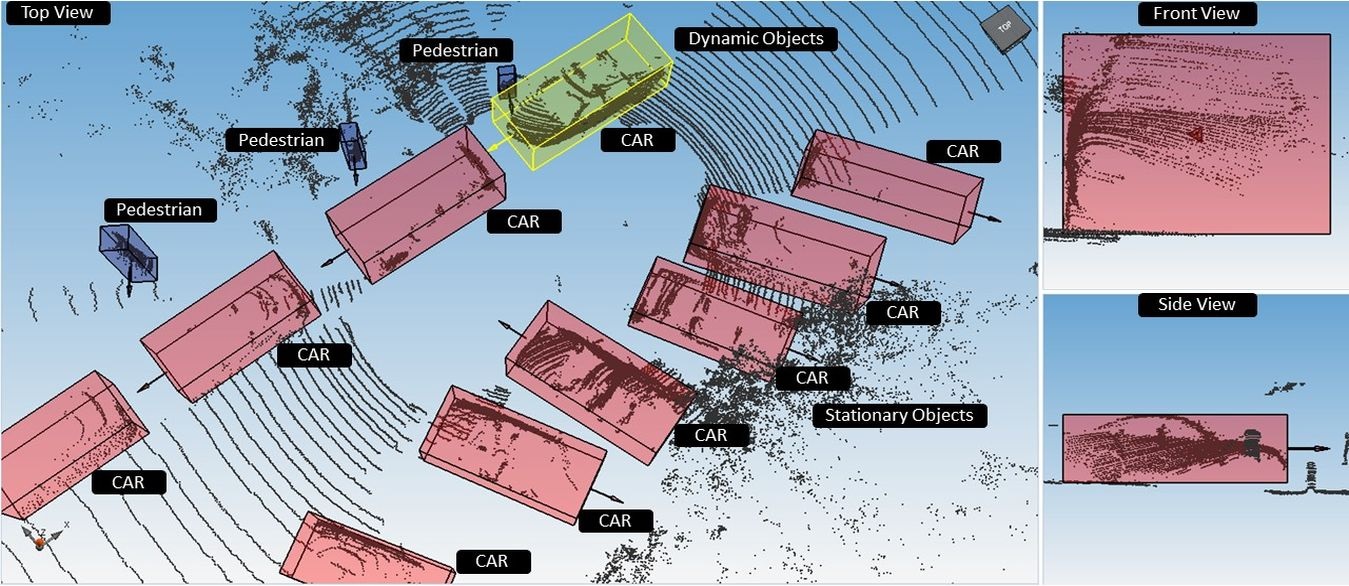

PLATFORM OVERVIEW
Accelerate model production with an advanced platform designed for scale
.jpg)
Iterative quality and calibration processes that scale
We provide the industry’s highest quality guarantee by employing the most comprehensive quality assurance processes. We work with you at the start of each project to collaboratively define what quality looks like and then provide in-depth training for all team members to drive consistency and eliminate high amounts of rework or lengthy delays
A collaborative space for project management and reporting
Leverage a centralized command center for annotation and validation workflows, quality review management, and reporting. You’ll get complete visibility into your projects and be able to directly collaborate with your dedicated Aimabec team. Plus, our suite of integrations makes onboarding easy so you can get started in days not weeks.Proactive human and tech-driven insights keep models on track
Our proprietary algorithms and human-in-the-loop approach enable our teams to identify actionable insights that help get models into production faster. From early edge case identification and senor or data distribution errors to deep visibility into model performance including exactly where and when models are failing to accurately predict outcomes.ASSURE
High Quality Data at Every Step
Quality Calibration
Quality calibration is our first step in every project. We work closely with you to create comprehensive quality rubrics built from mutually agreed upon golden tasks, aligning on error definitions and criticality for your model type.
We stay in continuous alignment with your team and can iterate on instructions and rubrics even after production has started to adapt to changing workflows and more accurately reflect the real world.
.jpg)
TRAINING
All of our teams are vertically segmented and understand the unique nuances of each industry—such as being an expert in the AgTech industry and being able to differentiate between different types of bugs and weeds.
Before project kickoff, all team members undergo rigorous 2-week, project-specific training and certification based on quality rubrics developed during the quality calibration phase ensuring they are subject matter experts on your workflows. Throughout your project, we invest in ongoing coaching and upskilling for continuous improvements to accuracy and precision.
AUTOMATED QA
Our Automated QA process automatically reviews all annotations and proactively catches any logical fallacies. Incorrect annotations are automatically surfaced saving our team 1-3 hours per day on average.
This enables our teams to dedicate more time to complex edge cases and more detailed workflows, allowing us to scale more consistently. After a task passes AutoQA it goes through a final check with our QA agents who catch any final errors before they are sent to you.

HUMAN QA
Once passing AutoQA all annotations go to a QA agent with an average of 4 years of experience. This final review provides an additional layer of review to help ensure quality and consistency at scale. They typically review the correctness and completeness of labels and flag unusual or challenging edge cases to proactively review with the client to ensure instructions are accurate.
For example, in one instance our team flagged that some cones were movable versus drilled into the ground. Rather than label everything a cone, we proactively updated instructions to label the drilled cones as barriers.

IQ
Proactive Insights That Help Train Models Faster
Our proprietary algorithm and human-in-the-loop approach surface insights that often prevent models from surviving in production environments.EDGE CASE AND TREND DETECTION
Incorporating early edge case and trend insights early in the data annotation and model training process helps strengthen the model's ability to handle diverse scenarios. It also enables ML teams to source more specific data to proactively fill in data diversity gaps. This reduces errors and unexpected failures, leading to faster and smoother processes in production.
SENSOR ERRORS
Our team proactively identifies various forms of sensor errors—from calibration issues, environmental factors, and hardware malfunctions to background noise and sensor sensitivity. Filtering out faulty data improves a model's ability to learn correct patterns and relationships and helps avoid unexpected failures in production.
DATA DISTRIBUTION
As we annotate and analyze your data, we’ll flag any distribution errors that could introduce biases or blind spots into your model—enabling you to proactively refine your training data sets. Our team also provides insights into the complexity and similarity of your data in order to better prioritize the data that is going to have the greatest impact on your model.
PERFORMANCE ANALYTICS
We help you drive toward model maturity by providing deeper visibility into where and why models are failing to predict accurate incomes. Understand model performance by class along with a complete error analysis highlighting false positives, false negatives, and misclassifications. These insights help highlight potential areas where biases might lie in your model and any deficient classes in your training data.
Data Security is Our Top Priority
Your data remains protected and private because it’s managed in a secure facility by full-time in-house workforce of data experts. Your Data is Yours – Aimabec Tech does not share or keep any datasets for training or other purposes, unlike crowdsourced alternatives.